Local LLMs using an AMD GPU - Part 1
I have been using GenAI a lot in my daily life, mainly ChatGPT, which I have found to be quite useful for troubleshooting issues, helping me develop faster, among other things. However, a big issue has always been privacy. GenAI, especially OpenAI’s ChatGPT, is quickly working its way into every facet of our computers - Apple’s “Apple Intelligence” with OpenAI partnership, Microsoft Copilot, GitHub Copilot, and so on. But they all rely on you using ChatGPT, and potentially giving your data away. Fortunately, there is an alternative - you can run LLMs (Large Language Models) locally, and completely offline.
However, I’ve been putting off trying to run them locally for a long time, since all I have in my desktop computer is an AMD RX 6700 XT. Until recently, I was vaguely aware that NVIDIA was the only way to go for running GenAI models, and I decided to take another look when I heard that AMD has since then gained more compatibility for running such models. I am fully aware that NVIDIA with its proprietary CUDA is still better for running local LLMs, which I might consider when buying a new computer in the future, but I wanted to see how far I could get with using what I had at hand.
Reasons
- Privacy - You can download and run the models completely offline, making sure that your data stays with you
- Cost - While OpenAI’s ChatGPT models are arguably the best on the market right now, if you already have the hardware, you can get some pretty good results with what you have and AMD cards are cheaper compared to NVIDIA, when you compare the amount of VRAM available
- Experimentation - You can experiment with the models and better fine-tune them for your needs, and get a better understanding of how LLMs work
Considerations
While it is possible to run LLMs locally, you must temper your expectations. It is possible to run LLMs without a GPU and only use a CPU, but the performance will be quite slow, and you’re still limited by the amount of RAM that you have available to load the models.
We’ll have to use smaller models that are still capable, but still nowhere near as powerful as what you might experience while using ChatGPT. I’ll be targeting models that are in the 7B-10B range (billions of parameters), and there are even smaller models available. While using a GPU really speeds up the token generation, you are still limited by the amount of vRAM on your GPU. To give you an idea of how much power is required to run really high-end models, take a look at this leaderboard for models: 1
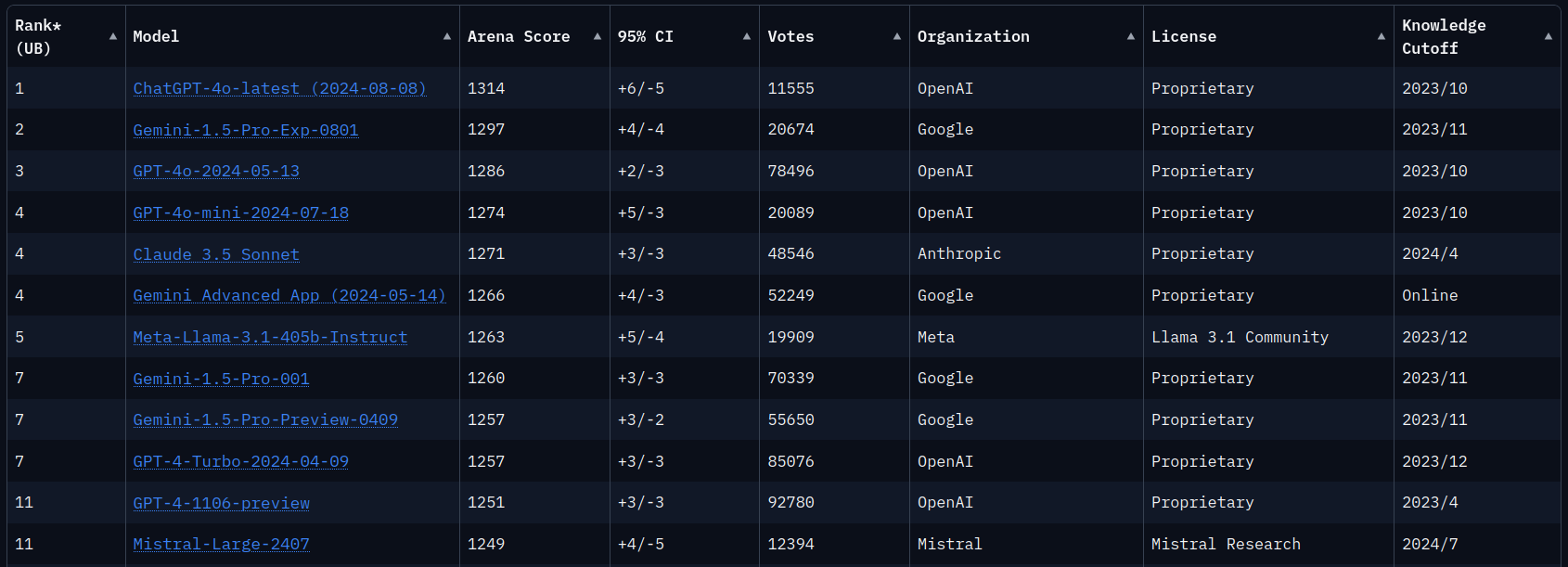
Let’s take the Llama 3.1 model with 405 billion parameters as an example, which trades blows with GPT 4o. To be able to get the most out of it, you require around 810 GB of vRAM2.
That is a lot. To put it in perspective, if you wanted to do this professionally and buy NVIDIA H100 cards with 80 GB each, which costs 30k€ each3, you’d need a cluster of about 12 of these cards in the data center.
With that being said, not every model out there is that large, and there’s a lot of work being done to optimize local LLMs and I want to take a look at the possibility of running them on my midrange consumer hardware and see what kind of use cases are viable.
LM Studio
For a start, I decided to try out LLMs with a user friendly UI, LM Studio. There are some other alternatives out there as well, such as GPT4All, which doesn’t have GPU support at the time of writing.
I installed LM Studio and downloaded the Llama 3.1 8B Instruct model. I noticed that the support for AMD graphics cards has gotten better lately, and I wanted to see how much better it feels to use my 6700 XT compared to my Ryzen 3700X processor. I’ve written a little test that queries the model via the API and asks it the question: “What can you tell me about the history of the European Union? Here’s a side-by-side comparison of a test query I did, one that uses the CPU entirely and the other that uses the GPU:
CPU:
time python eutest.py
ChatCompletionMessage(content="The European Union (EU) has a rich and complex history that spans over seven decades. ...", refusal=None, role='assistant', function_call=None, tool_calls=None)
real 1m47.265s
user 0m0.520s
sys 0m0.208s
GPU:
time python eutest.py
ChatCompletionMessage(content="The European Union (EU) has a rich and complex history that spans over seven decades. ...", refusal=None, role='assistant', function_call=None, tool_calls=None)
real 0m15.527s
user 0m0.463s
sys 0m0.241s
That is nearly 7 times faster than using only the CPU, which is quite impressive!
In LM Studio, you turn on and off the usage of the graphics card here:
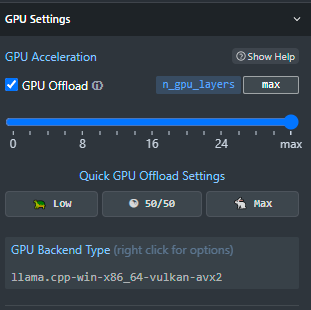
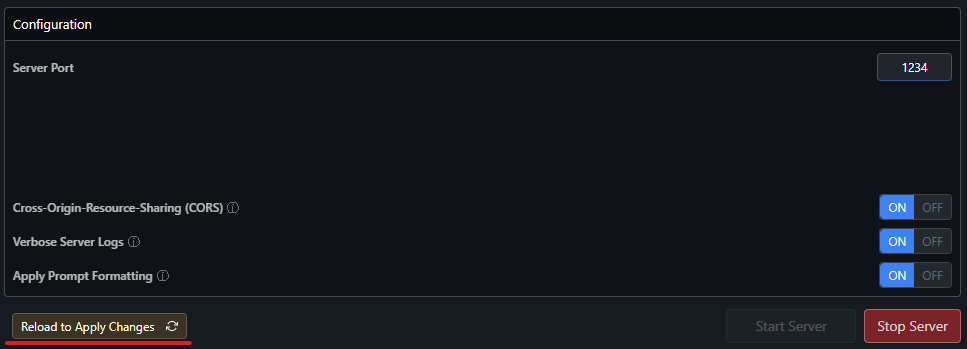
You can also choose to do a mixture of CPU/GPU usage. For this test, I have opted for max offload, and GPU offload completely turned off for the test. After you make changes here, you do need to reload the model:
Ollama
While LM Studio is a great start to download models and play around with them out-of-the-box, I’ve found the API server that it creates to be somewhat limiting, so I decided to try Ollama next. Ollama is also similar in that you can download the models pretty hassle-free, however, it does not have a GUI and you’ll have to rely more on a terminal.
Installation
Unfortunately, it seems like at the time of the writing, my 6700 XT GPU is not officially supported on Linux at the moment. Ollama uses the AMD ROCm library, and my graphics card is not included in the list of supported cards45:
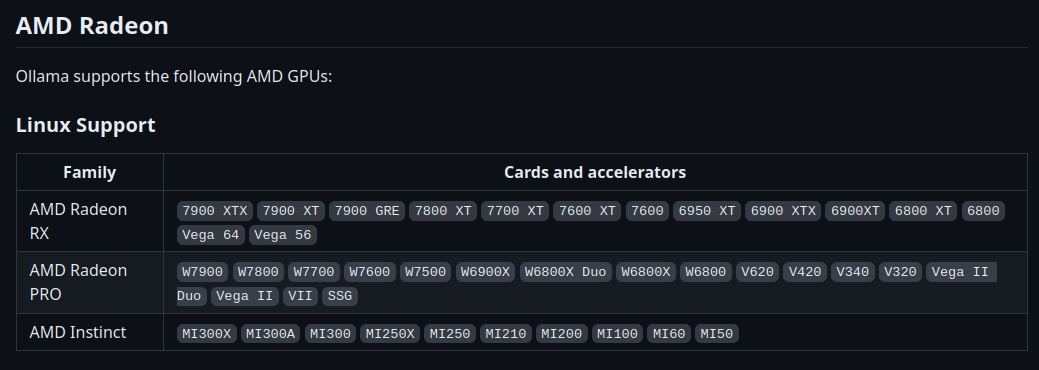
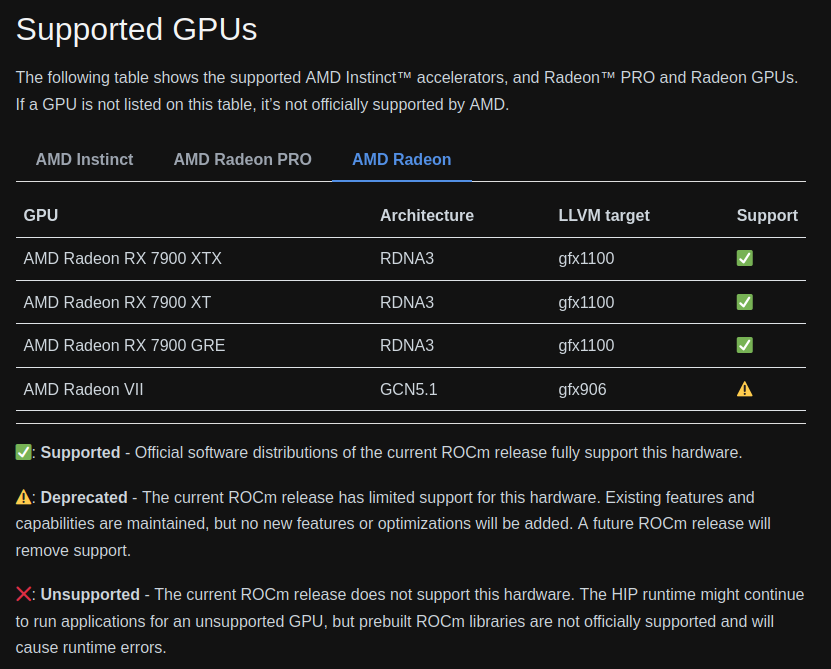
However, they mention in the documentation from ollama that you can set an environment variable to overcome this limitation, which I what I’ve tried:
export HSA_OVERRIDE_GFX_VERSION="10.3.0"
ollama serve
ollama run llama3.1
ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:latest 91ab477bec9d 6.7 GB 100% GPU 4 minutes from now
It works! With the correct setting, I was able to get a very impressive speed compared to pure CPU usage as well.
Since I’ve installed ollama through the package manager, I’ve added in the environment variable into the systemd unit file with the following:
sudo systemctl edit ollama
### Editing /etc/systemd/system/ollama.service.d/override.conf
### Anything between here and the comment below will become the contents of the drop-in file
[Service]
Environment="HSA_OVERRIDE_GFX_VERSION=10.3.0"
### Edits below this comment will be discarded
If you are using the Docker version, you can pass it in with -e instead.
What’s Next?
There are plenty of other ways of getting LLMs working locally, but I think this is a good start. The topics that I would like to focus on in the second part is:
- How we can work with these local LLMs?
- How good are the results?